
Your coding agent can read the file in front of it, but that does not mean it understands your business. Most bad suggestions do not come from weak syntax knowledge; they come from missing context about why the code exists, who owns it, and what usually breaks with it.
That is where repository intelligence changes the game. Instead of treating your repo like a folder of files, it turns it into a living map of history, dependencies, ownership, risks, and intent.
What Is Repository Intelligence?
Repository intelligence is the practice of building a deep, connected understanding of your codebase before making recommendations, writing code, reviewing pull requests, or generating documentation.
Think of it like the difference between asking a new developer to fix a bug on day one versus asking a senior engineer who has worked on the product for five years. The senior engineer knows:
- Which files usually change together
- Which modules are risky to touch
- Who owns a service or feature
- Which parts of the system are legacy or dead code
- Why a strange workaround exists
- Where tests are missing or unreliable
- Which architectural decisions shaped the current design
Repository intelligence gives your coding workflow more of that senior-engineer context. It does not just inspect code. It connects code to history, behavior, ownership, intent, and business risk.
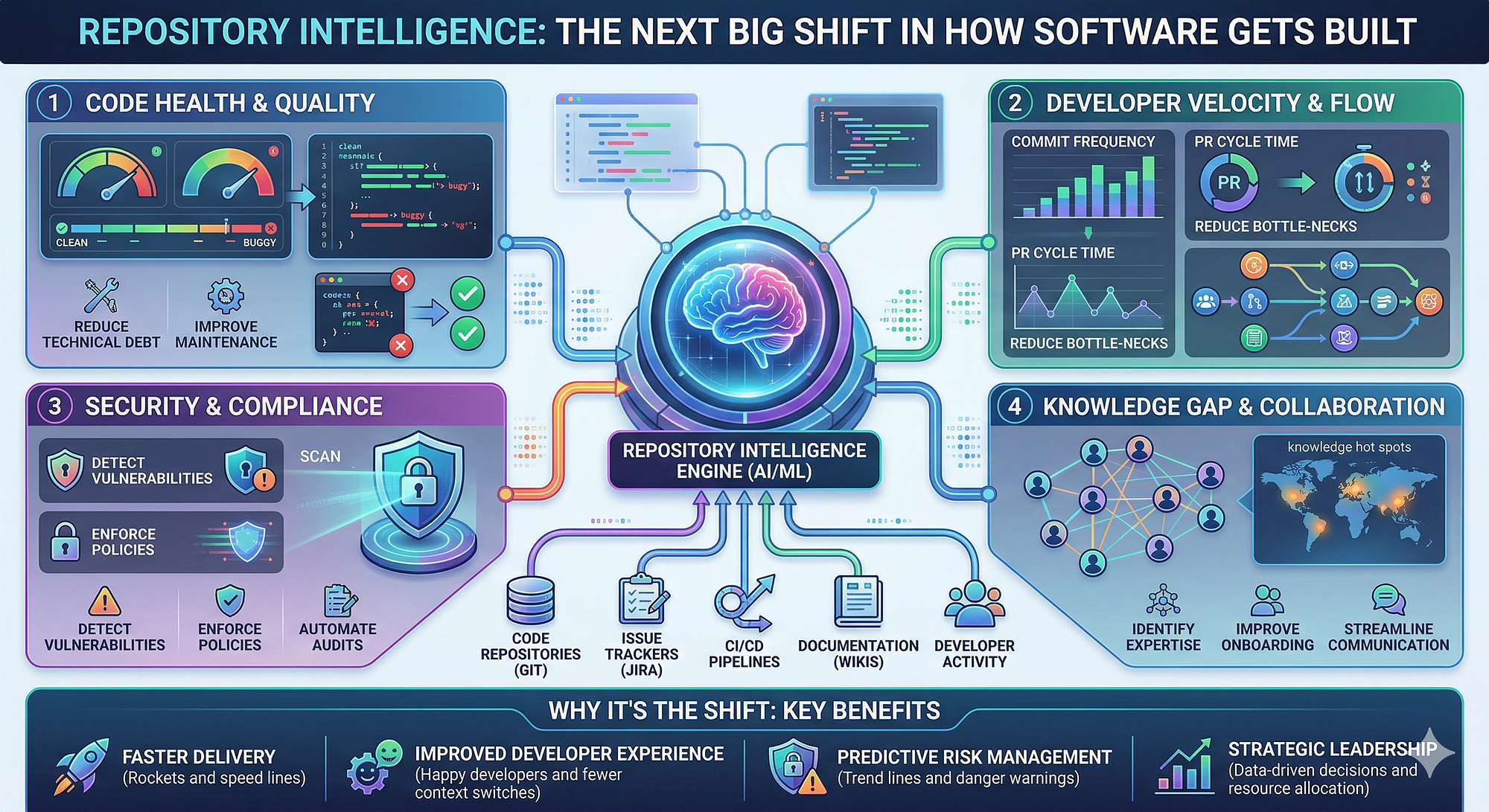
Why Normal Coding Agents Still Miss the Big Picture
Most coding agents are good at local tasks. Ask them to explain a function, refactor a class, or write a unit test, and they can often help. But businesses do not fail because one function was slightly messy. They lose time because changes ripple through systems nobody fully understands.
Your coding agent may read files, but it usually does not automatically know:
- Who last maintained a module
- Which files are frequently changed in the same pull request
- Which tests have historically failed around that area
- Which old decisions explain the current architecture
- Which code is unused but still dangerous to remove
- Which service boundaries should not be crossed
That gap creates confident but risky output. The code may look correct in isolation while quietly violating an architectural pattern, duplicating existing logic, or breaking an unspoken dependency.
7 Reasons Your Business Needs Repository Intelligence
1. It Makes Code Suggestions Safer
The biggest benefit is simple: fewer bad changes.
When a coding agent understands the repository graph, it can see relationships between files, services, packages, owners, and previous changes. That means it can avoid suggestions that look fine locally but are dangerous globally.
For example, if two files almost always change together, repository intelligence can flag that relationship. If a proposed change touches a payment service with weak test coverage, it can raise the risk level. If a function looks unused but is called through reflection, config, or a generated route, the system can warn before someone deletes it.
2. It Improves Code Review Quality
A good code review is not just “does this compile?” It asks, “Does this change fit the system?”
Repository intelligence can support better reviews by surfacing:
- Related files reviewers should inspect
- Past bugs in the same area
- Ownership signals for better reviewer assignment
- Risky dependencies affected by the change
- Missing tests based on historical patterns
This is where concepts like a code review graph, GitHub code graph, or knowledge graph for a coding agent become practical. The goal is not to make review more complicated. It is to help reviewers spend their attention where it matters most.
3. It Captures Tribal Knowledge Before It Disappears
Every engineering team has invisible knowledge. Someone knows why the billing module is weird. Someone remembers why the monolith cannot call a certain service directly. Someone knows which cron job looks dead but must never be removed.
The problem? People change teams. They leave. They forget.
Repository intelligence helps convert that tribal knowledge into a navigable system by connecting:
- Pull request discussions
- Commit history
- Architecture decision records
- Documentation
- Test behavior
- Ownership metadata
- Issue tracker context
This is especially valuable because documentation, tests, and ADRs used to be expensive to maintain. Teams skipped them because deadlines won. Now, generating and updating them can be much faster, especially when the system already understands the repository context.
4. It Helps New Developers Ramp Up Faster
Onboarding is one of the most expensive hidden costs in engineering. A new developer may spend weeks asking, “Where is this handled?” or “Why is this built this way?”
With repository intelligence, a new teammate can ask better questions and get better answers:
- “What owns user authentication?”
- “Which services does checkout depend on?”
- “What changed the last time this test failed?”
- “Who should review changes in this directory?”
- “Is this module actively maintained?”
Instead of wandering through folders, they get a map. That means faster ramp-up, fewer interruptions for senior engineers, and less risk from early mistakes.
5. It Finds Dead Code and Hidden Risk
Most mature codebases contain code nobody wants to touch. Some of it is truly dead. Some of it is critical but poorly understood. The hard part is telling the difference.
Repository intelligence can help identify:
- Files that have not changed in years
- Modules with no clear owner
- Code with declining test coverage
- Areas with high bug frequency
- Functions that appear unused but are indirectly referenced
This gives leaders a clearer view of technical debt. Not vague complaints like “the codebase is messy,” but specific, evidence-backed signals about where risk lives.
6. It Makes Documentation and Tests Easier to Maintain
Documentation often fails because it is separate from the work. Someone writes it once, then the code changes, and the docs slowly rot.
Repository intelligence can reduce that gap by connecting documentation to actual code paths, ownership, and change history. When a core workflow changes, the system can identify related docs, tests, and ADRs that may need updates.
The same applies to tests. Instead of blindly generating tests for a single file, a smarter workflow can ask:
- What behavior is this module responsible for?
- Which tests already cover related paths?
- What edge cases caused bugs before?
- Which integration points are most fragile?
That leads to tests that are not just more numerous, but more relevant.
7. It Gives Engineering Leaders Better Decisions
Repository intelligence is not only for developers. It helps managers, architects, and technical leaders answer business-critical questions:
- Where are we carrying the most risk?
- Which systems depend on one or two people?
- Which parts of the product slow delivery?
- Where should we invest in refactoring?
- Are teams following architectural boundaries?
This turns engineering planning from opinion-driven to evidence-driven. Instead of relying only on gut feel, leaders can use repository signals to prioritize the work that improves velocity and reliability.
Repository Intelligence vs. Basic Code Search
| Capability | Basic Code Search | Repository Intelligence |
|---|---|---|
| Finds text in files | Yes | Yes |
| Understands file relationships | Limited | Strong |
| Uses commit and PR history | No | Yes |
| Identifies ownership | No | Yes |
| Flags risky changes | No | Yes |
| Connects docs, tests, and ADRs | No | Yes |
| Supports better review routing | No | Yes |
What to Look for in a Repository Intelligence System
If you are evaluating this for your business, do not stop at “can it read code?” That is the bare minimum. Look for a system that can build a rich map of your repository over time.
Prioritize these capabilities:
- Code graph mapping: Understands dependencies, imports, calls, services, and shared components.
- Git history analysis: Uses commits and pull requests to detect change patterns.
- Ownership detection: Identifies likely maintainers and reviewers.
- Risk scoring: Flags fragile areas based on churn, bugs, coverage, and complexity.
- Documentation awareness: Connects code to docs, ADRs, tickets, and design notes.
- Review assistance: Suggests what reviewers should inspect and why.
- Security and privacy controls: Respects your source code, permissions, and compliance needs.

How to Start Without Boiling the Ocean
You do not need to map everything perfectly on day one. Start with one high-value workflow.
- Pick a painful area: Choose code review, onboarding, test generation, or technical debt discovery.
- Connect your repository history: Include commits, pull requests, file changes, and ownership signals.
- Map relationships: Identify services, packages, modules, tests, and docs that connect to each other.
- Use it in real work: Apply it to active pull requests or onboarding tasks.
- Measure outcomes: Track review time, escaped bugs, onboarding speed, and developer satisfaction.
The best approach is practical. Do not build a beautiful graph nobody uses. Build a useful map that helps teams make better changes this week.
FAQ
What is repository intelligence in simple terms?
Repository intelligence is a deeper understanding of your codebase that includes code relationships, Git history, ownership, documentation, tests, and architectural intent. It helps coding agents and teams make better decisions because they can see the full context, not just one file.
Is repository intelligence the same as a code graph?
Not exactly. A code graph is usually one part of repository intelligence. Repository intelligence may include a code graph, but it also includes change history, pull request patterns, ownership, test coverage, docs, ADRs, and risk signals.
How does repository intelligence improve code review?
It helps reviewers understand what else might be affected by a change. It can suggest related files, identify risky modules, recommend reviewers, and surface historical context from past bugs or pull requests.
Do small engineering teams need repository intelligence?
Yes, especially if the product is growing. Small teams often rely heavily on memory and informal knowledge. Repository intelligence helps preserve that knowledge before complexity increases or key people move on.
Can repository intelligence help with documentation?
Absolutely. It can identify which docs relate to which code paths, detect when docs may be stale, and help teams create better ADRs, onboarding guides, and test plans based on real repository context.

Final Recommendation
If your business uses coding agents without repository intelligence, you are asking them to work like a developer who just joined the company five minutes ago. They may be helpful, but they are still guessing.
The best next step is to add a repository intelligence layer before relying on automated code suggestions, reviews, or refactors at scale. Start with code review or onboarding, connect your Git history and ownership signals, and build from there. Your team will move faster, but more importantly, they will move with far less risk.