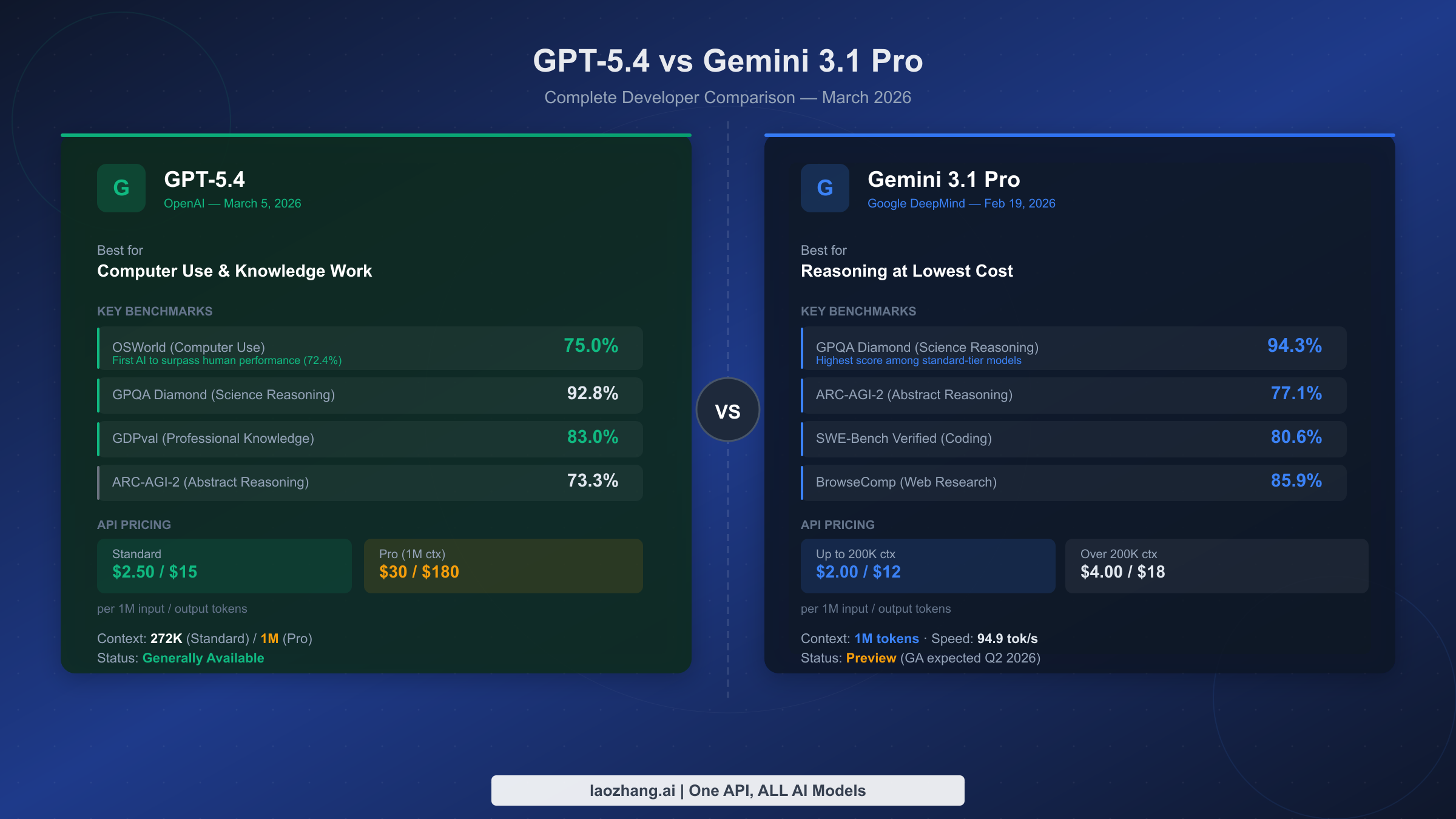
Most developer model comparisons obsess over leaderboard wins, but that is not what drains your budget. The real question is simpler: which model helps you ship reliable code faster without making your monthly bill look ridiculous?
If you are choosing between Gemini 3.1 Pro and GPT-5.4, the answer depends less on “which one is smarter” and more on what kind of developer work you actually do every day.
GPT-5.4 vs Gemini 3.1 Pro: The Real Developer Value Test
For serious coding work, GPT-5.4 is the stronger overall choice. It tends to perform better on complex reasoning, multi-step agentic tasks, tool use, debugging across unfamiliar systems, and high-stakes code generation where one subtle mistake can waste hours.
But Gemini 3.1 Pro is not just a “cheap alternative.” It is surprisingly capable, especially when the task involves reading an existing codebase, following project patterns, and making practical changes without over-engineering the solution.
That makes this comparison more interesting than a simple winner-takes-all fight. The better question is:
- Are you paying for maximum coding reliability?
- Or are you optimizing for cost-effective developer productivity?

Quick Comparison Table
| Category | GPT-5.4 | Gemini 3.1 Pro | Best Value Winner |
|---|---|---|---|
| Complex coding | Excellent for deep reasoning, architecture, debugging, and agents | Strong, but less consistent on very complex tasks | GPT-5.4 |
| Everyday coding tasks | Very strong, sometimes overpowered | Fast, practical, and cost-effective | Gemini 3.1 Pro |
| Existing codebase awareness | Strong, especially with good prompting | Often excellent at reading project context | Gemini 3.1 Pro |
| Agent workflows | Best choice for tool orchestration and multi-step execution | Capable, but less ideal for premium automation | GPT-5.4 |
| Budget value | Premium performance at premium cost | Better for high-volume standard use | Gemini 3.1 Pro |
Where GPT-5.4 Wins for Developers
If your work involves anything beyond simple autocomplete or boilerplate generation, GPT-5.4 starts to justify its premium positioning quickly.
1. Coding-heavy agents
GPT-5.4 is the better pick when you are building agents that need to plan, call tools, inspect results, recover from errors, and continue working without constant hand-holding.
This matters for workflows like:
- Automated pull request creation
- Repository-wide refactoring
- Test generation and repair loops
- CI/CD troubleshooting
- Codebase migration projects
For these tasks, the cheapest model is rarely the best value. A model that saves tokens but makes poor tool decisions can cost more in rework, failed runs, and developer supervision.
2. Computer-use workflows
When a model needs to interact with browsers, terminals, IDEs, dashboards, or multiple tools in sequence, GPT-5.4 has the edge. It is better suited for tasks where the workflow is not just “write code,” but “understand the environment, choose the right action, execute, verify, and adapt.”
That makes it the stronger option for premium developer automation products, internal engineering assistants, and complex QA systems.
3. Hard debugging and architectural reasoning
GPT-5.4 tends to shine when the problem is vague, layered, or messy. For example:
- “This service randomly times out under load.”
- “Find why this authentication flow breaks only in staging.”
- “Refactor this module without changing behavior.”
- “Design a safer queue processing system.”
These are not simple coding prompts. They require inference, tradeoff analysis, and a good sense of engineering risk. GPT-5.4 is generally the safer bet when correctness matters more than cost.

Where Gemini 3.1 Pro Delivers Better Value
Gemini 3.1 Pro’s biggest advantage is not that it beats GPT-5.4 everywhere. It does not. Its advantage is that it can handle a surprisingly large amount of normal developer work at a lower cost.
1. Standard development tasks
For everyday tasks, Gemini 3.1 Pro is often more than enough. Think:
- Writing utility functions
- Explaining unfamiliar code
- Generating unit tests
- Improving error messages
- Creating API examples
- Converting code between frameworks
If your team is using model assistance across many developers and thousands of prompts, this matters. Small per-request savings can turn into meaningful monthly savings.
2. Contextual awareness in existing codebases
One of the more interesting things about Gemini 3.1 Pro is how well it can handle certain codebase-aware tasks. In practical tests, it has handled tasks like rate limiting correctly while showing strong awareness of surrounding project structure.
That is exactly what many developers need: not a model that invents a beautiful new architecture, but one that reads the existing code, respects the current style, and makes the smallest useful change.
3. Budget-conscious teams
Gemini 3.1 Pro makes a lot of sense for startups, solo developers, internal tools teams, and engineering groups that want broad adoption without premium spend on every task.
A smart setup might look like this:
- Use Gemini 3.1 Pro for standard coding, explanations, documentation, and simple bug fixes.
- Escalate to GPT-5.4 for complex architecture, agent workflows, and high-risk code changes.
- Track failure rate, rework time, and cost per successful task instead of only token price.
What About GPT 5.5 vs Gemini 3.1 Pro?
Many developers also ask about GPT 5.5 vs Gemini 3.1 Pro. According to rankings such as the Artificial Analysis Intelligence Index, GPT 5.5 is often positioned as a leading overall model, including strong coding performance.
That said, the value question stays the same. If GPT 5.5 is available to you at a reasonable price, it may outperform GPT-5.4 and Gemini 3.1 Pro on many advanced tasks. But if cost is a major factor, Gemini 3.1 Pro can still be the better day-to-day option for routine development work.
Best way to think about it: GPT 5.5 may be the performance ceiling, GPT-5.4 is the premium practical choice, and Gemini 3.1 Pro is the budget-value workhorse.

Gemini 3.1 Pro vs Claude Opus 4.6 for Coding
Claude Opus 4.6 is another strong option developers compare against Gemini 3.1 Pro. Opus models are often appreciated for careful reasoning, readable explanations, and strong long-form code analysis.
If your work is heavily focused on code review, architectural critique, or long-context reasoning, Claude Opus 4.6 can be highly competitive. But if the choice is specifically between Gemini 3.1 Pro and GPT-5.4 for best developer value, GPT-5.4 remains the stronger premium coding pick, while Gemini remains the more cost-conscious option.
Opus 4.6 vs GPT-5.4 High: Which Should Advanced Teams Pick?
For advanced teams comparing Opus 4.6 vs GPT-5.4 high-tier usage, the decision usually comes down to workflow. GPT-5.4 is especially compelling for tool-heavy agents and interactive development systems. Opus 4.6 may be attractive for thoughtful analysis, documentation-heavy work, and careful review.
If your system depends on models taking action through tools, GPT-5.4 is usually the safer premium bet. If your team wants another strong reviewer or reasoning partner, Opus 4.6 deserves testing.
How to Choose the Right Model for Your Workflow
Here is the simplest decision framework:
Choose GPT-5.4 if:
- You are building production-grade coding agents.
- You need reliable tool orchestration.
- Your prompts involve multiple files, hidden dependencies, and edge cases.
- You care more about correctness than cost.
- You are automating workflows where failure is expensive.
Choose Gemini 3.1 Pro if:
- You want lower-cost help for everyday coding.
- You need strong codebase reading for standard tasks.
- You are supporting many developers or high-volume usage.
- You can tolerate occasional escalation to a stronger model.
- You want the best value for routine development assistance.
The Best Setup: Use Both Strategically
The highest-value teams will not treat this as a religious debate. They will route tasks intelligently.
Use Gemini 3.1 Pro as the default for common work. Then bring in GPT-5.4 when the task becomes complex, expensive to get wrong, or requires advanced tool use.
This hybrid approach gives you the best of both worlds: Gemini’s cost efficiency and GPT-5.4’s premium reliability.
FAQ
Is GPT-5.4 better than Gemini 3.1 Pro for coding?
Yes, for advanced coding tasks, GPT-5.4 is generally better. It is the stronger choice for complex debugging, agents, tool orchestration, and high-stakes engineering workflows.
Is Gemini 3.1 Pro good enough for developers?
Yes. Gemini 3.1 Pro is very capable for standard development tasks such as code explanation, simple bug fixes, test generation, documentation, and working within existing project patterns.
What is GPT-5.4 Pro?
Developers often use “GPT-5.4 Pro” to refer to a premium or higher-capability GPT-5.4 experience. The key idea is that GPT-5.4 is best used where stronger reasoning and reliability justify the cost.
Should I use GPT 5.5 instead of GPT-5.4?
If GPT 5.5 is available to you and priced reasonably, it may be the better performance choice. But GPT-5.4 still offers a strong premium coding experience, especially compared with lower-cost alternatives.
Which model gives the best value overall?
For heavy engineering automation, GPT-5.4 gives the best value because it reduces failure and rework. For routine developer assistance at scale, Gemini 3.1 Pro is the better value because it keeps costs lower while still performing well.
Final Recommendation
If you are doing serious coding work, building agents, orchestrating tools, or automating developer workflows where mistakes are expensive, choose GPT-5.4. It is the stronger premium model and the better fit for complex engineering use cases.
If you are budget-conscious and mostly need help with standard development tasks, choose Gemini 3.1 Pro. It is capable, cost-effective, and often smart enough to handle the work developers actually do every day.
The best value move is simple: use Gemini 3.1 Pro by default, and escalate to GPT-5.4 when the task demands premium reasoning.